layout: default title : Modèle de chapitre pour 2022 date: 2022-01-10 22:00:00 +0100 —
janvier 2022
Nous somme 5 étudiants en dernière année à Polytech’ Nice-Sophia en spécialité Architecture Logicielle :
Ce chapitre est écrit dans le cadre du module Retro-ingénierie, maintenance et évolution et logiciels (RIMEL) de dernière année de cycle ingénieur à l’école Polytech Nice Sophia.
Plusieurs sujets de recherche ont été proposés aux groupes d’étudiants parmi lesquels : extraire des informations sur les systèmes de build (variabilité des builds), sujet que nous avons choisis. À la lecture du sujet, l’une des premières choses que nous nous sommes dit est l’idée selon laquelle la variabilité d’un système est forcément reflétée sur sa chaîne de CI. À une époque où les fausses informations se véhiculent principalement par les impressions, nous pensions cela intéressant de vérifier la véracité de cette ‘impression’. Nous nous sommes aussi intéressés à ce sujet afin de parfaire nos connaissances sur les CI de système où nous avons peu d’expérience.
Dans notre étude, nous admettrons que configurabilité et variabilité sont des termes similaires car cela est hors de notre contexte. Pour voir s’il y a une différence entre les termes , il faudrait faire une étude bibliographique sur la “configurabilité” et la “variabilité”.
Enfin, nous tentions initialement de répondre à la problématique suivante : est-ce qu’une forte variabilité d’un système implique une forte variabilité de sa CI ? Mais cette problématique, assez large, a été redécoupée en plusieurs sous questions dont l’une sera le sujet de ce chapitre.
Nous avons commencé notre travail par l’étude d’un premier système, freeBSD, dont nous parlerons plus précisément en fin de chapitre, et les premiers résultats trouvés nous ont tout de suite orienté vers une nouvelle question qui constituera notre étude et le contenu de cet article. </br> En effet, nous avons remarqué que la variabilité de la CI de freeBSD était composée en majorité de points de variations en lien avec la plateforme (qu’elle soit matérielle ou logicielle). Nous reviendrons sur cette démarche dans la partie suivante. </br> Nous avons donc recentré notre question sur les liens qui existent entre variabilité du système et de la CI au niveau de la plateforme. </br> La problématique sur laquelle nous avons travaillé tout au long de ce module est donc la suivante : est-ce que posséder une variabilité de plateforme au sein d’un système (matérielle ou logicielle) implique une variabilité de la CI ?
Afin de choisir des projets qui constitueront notre base de travail, nous nous sommes posés les questions suivantes:
Pour déterminer la variabilité d’un système nous nous sommes reposés sur le chapitre [1] qui propose un framework de termes et de concepts à propos de la variabilité dans les systèmes. La variabilité d’un système est définie par le fait que celui-ci propose des fonctionnalités pour lesquelles il existe plusieurs variantes. Pour identifier les points de variation du système, nous nous sommes basés sur ce même chapitre, qui réalise des diagrammes de fonctionnalités pour identifier les points de variabilité. Ces points de variations peuvent apparaître au moment de la compilation ou du runtime. On retrouve des directives de préprocesseur (#ifdef, #if, #else …), aussi appelées compilation conditionnelle, dans du code C/C++, et pour le Java on retrouve des mécanismes orientés objet. Nous analyserons uniquement les systèmes utilisant le préprocesseur C afin de restreindre les nombreuses possibilités . Nous nous référons à le chapitre [2] qui analyse la variabilité de plusieurs systèmes Open Source utilisant les directives de préprocesseur et détaille comment en extraire des informations. Notre métrique d’évaluation de la variabilité d’un système correspond au nombre de ces directives dans le code, qui serait synonyme du nombre de points de variations ainsi que le nombre de constantes de configurations présentes dans les fichiers (SDFiles). Concernant les métriques pour la chaîne d’intégration, il s’agit du nombre de jobs Concernant la zone de recherche, nous avons décidé de choisir GitHub qui est facile à utiliser et qui répertorie de nombreux projets. Pour sélectionner les projets nous nous sommes basés sur : un projet OpenSource utilisant le Préprocesseur C qui comporte des fichiers de configuration CI. Nous avons étudié FreeBSD, Redis, la calculette Windows, OpenVPN et OpenCorePkg qui sont des systèmes Open Source implémentés en partie en C/C++. Nous avons utilisé le logiciel CppStats qui permet d’obtenir des mesures sur la variabilité des systèmes basés sur le préprocesseur C.
Afin de vérifier l’assertion selon laquelle un système ayant une configurabilité au niveau de la plateforme implique une configurabilité de sa CI, nous avons simplement étudié un ensemble de systèmes, sur chaque système nous avons étudié le pourcentage de variabilité concernant l’OS ou l’architecture puis nous avons étudié la configurabilité de leurs CI.
Ainsi nous avons formulé deux hypothèses:
Dans un premier temps, nous avons recherché manuellement des similarités dans le repository github du code source et de la CI de FreeBsd et nous y avons déduit un protocole à appliquer pour nos autres analyses de projets. Dans le code source, nous avons cherché les occurrences des “#ifdef” qui correspondent aux directives de compilation conditionnelles. Nous nous sommes basés sur les mots clés ( #ifdef, #if ) qui correspondaient à notre corpus de mots pour détecter les points de variabilités au sein du code source car les variables présentes dans les #ifdef représentaient les conditions d’exécution du code.</br> Afin de simplifier l’étude, nous avons considéré que la présence d’un #ifdef correspond à un point de variabilité dans le projet bien que cela ne soit pas toujours le cas.</br> Parmi les limites que nous avons identifiées, nous utilisions uniquement les #ifdef comme critère de variabilité dans notre recherche cependant, il doit exister d’autres méthodes. </br> De plus, les conditions des directives de compilation trouvées ne correspondaient pas forcément à un point de variation. (ex : #ifdef __DEBUG__) Lors de la recherche dans le code source nous avons trouvé la présence de nombreux mots clés et avons cherché les occurrences de chaque conditions de variabilité dans les fichiers. ( plus de 20000 #ifdef) </br> Parmi les variables trouvées, certaines étaient dédiées au développement ( ACPI_DEBUG), et d’autres correspondaient à des points de variabilités en fonction du système d’exploitation (__linux__, _WIN32) ou de l’architecture du micro processeur (amd64, i386, arm64, powerpc, riscv…). Avec ces informations nous pouvions déjà affirmer que le système étudié était variable au niveaux de la plateforme.</br> Les autres points de variabilités correspondaient au métier, étaient propres à l’application ou étaient inconnus. Pour déterminer les autres types de variabilités nous avons récupéré toutes les conditions de compilation différentes en utilisant cppStats et nous avons développé un script Python permettant de compter le nombre d’occurrence de chacunes d’elles. </br>
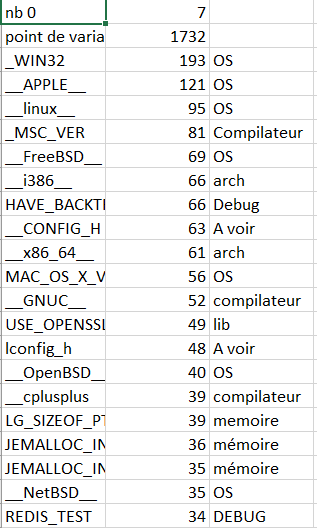
</br>
Nous avons identifié le type de variabilité auquel les conditions appartenaient et nous les avons ajoutées à notre dictionnaire de données. Cela permet de rechercher et d’identifier les types de variabilité dans les autres projets. De plus, ces metrics permettaient de savoir si le système et la CI étaient peu ou fortement variables.
</br>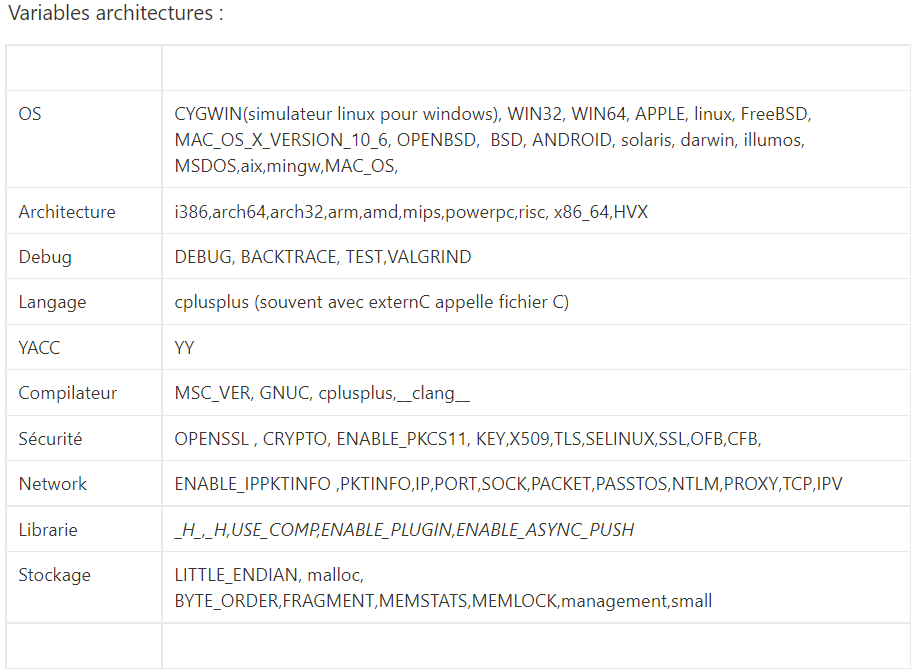 <figcaption align = "center">Dictionnaire de mots</figcaption>
<figcaption align = "center">Dictionnaire de mots</figcaption>
Pour la chaîne d’intégration continue nous avons étudié manuellement chaque CI, nous nous sommes basés sur le nombre de jobs et la corrélation avec la variabilité du système pour déterminer si la CI était variable et en lien avec le système.
Une fois le protocole d’expérimentations mis en place nous avons pu le tester sur différents projets. Nous allons maintenant vous présenter les résultats obtenu sur ceux-ci.
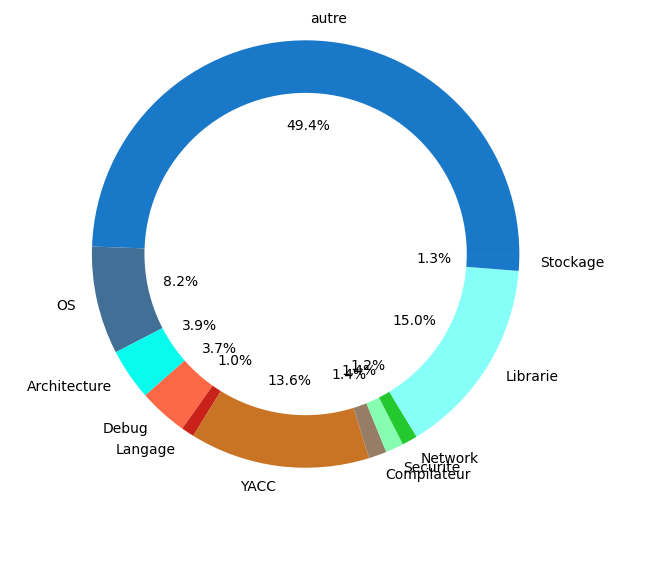 <figcaption align = "center">Freebsd code source</figcaption> <figcaption align = "center">Freebsd code source</figcaption> |
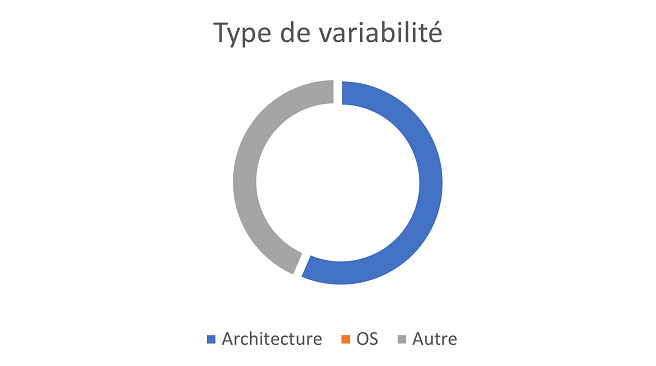 <figcaption align = "center">Freebsd CI</figcaption> <figcaption align = "center">Freebsd CI</figcaption> |
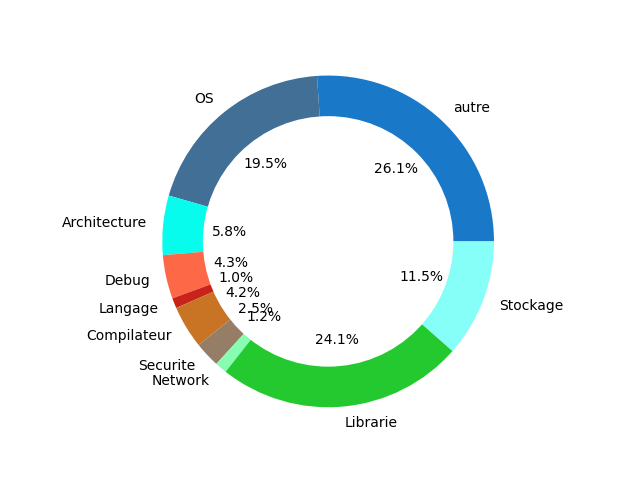 <figcaption align = "center">Redis code source</figcaption> <figcaption align = "center">Redis code source</figcaption> |
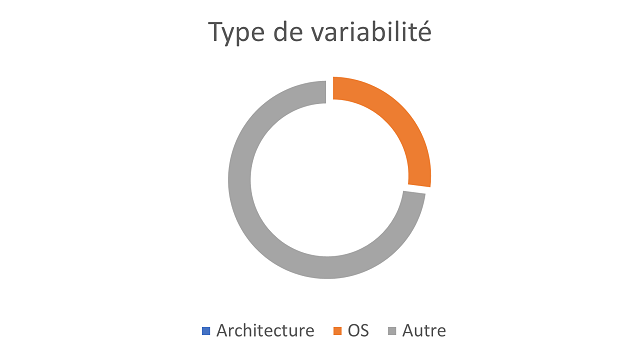 <figcaption align = "center">Redis CI</figcaption> <figcaption align = "center">Redis CI</figcaption> |
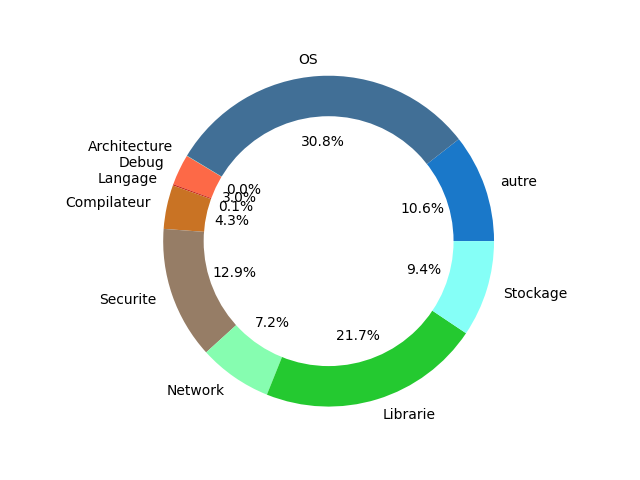 <figcaption align = "center">OpenVPN code source</figcaption> <figcaption align = "center">OpenVPN code source</figcaption> |
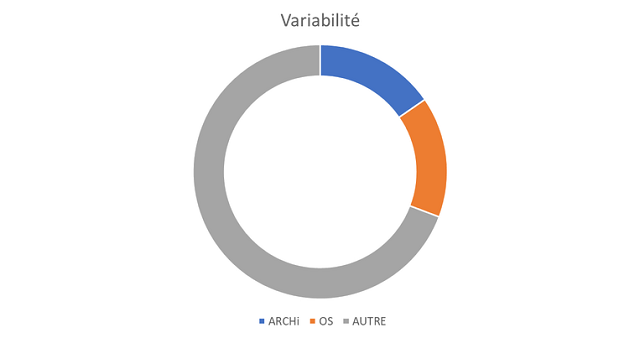 <figcaption align = "center">OpenVPN CI</figcaption> <figcaption align = "center">OpenVPN CI</figcaption> |
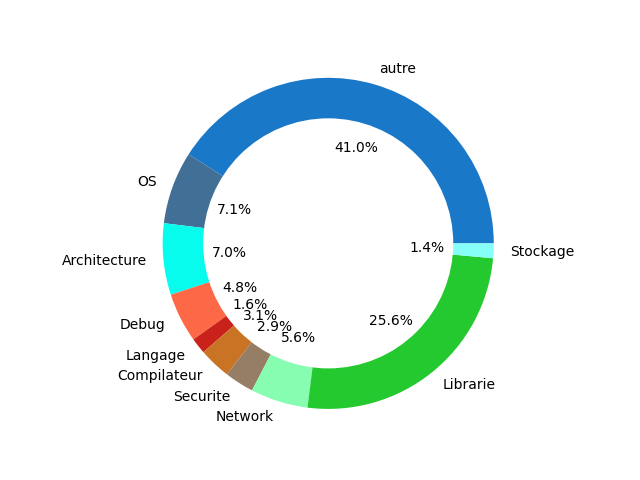 <figcaption align = "center">OpenCorePgk code source</figcaption> <figcaption align = "center">OpenCorePgk code source</figcaption> |
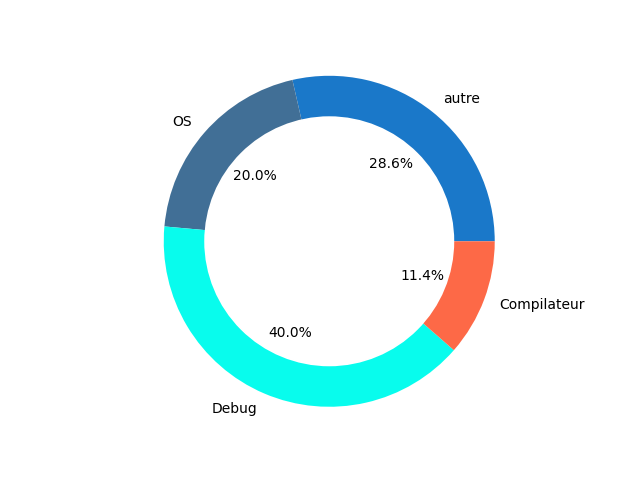
 <figcaption align = "center">OpenCorePgk CI</figcaption> <figcaption align = "center">OpenCorePgk CI</figcaption> |
 <figcaption align = "center">Windows Calculator code source</figcaption> <figcaption align = "center">Windows Calculator code source</figcaption> |
 <figcaption align = "center">Windows Calculator CI</figcaption> <figcaption align = "center">Windows Calculator CI</figcaption> |
Précision:
Les pourcentages côté CI sont calculés de la manière suivante (Nbr d’os ou archi unique/Nbr de job total)
La partie “autre” dans les CI, représente en partie des jobs liés à de la documentation, mais également les jobs de type build, test … redondant pour chaque archi/OS
Ces diagrammes montrent des résultats de variabilité côté système et CI selon leur type.
Grâce à ces données nous pouvons créer un tableau d’association des variabilités OS/Archi:
| Système | CI |
|---|---|
| OS | Archi |
| Archi | - |
| OS+Archi | OS || OS+Archi |
| Aucun | - |
Comme on peut le voir sur ce tableau il nous faudrait plus de projets ( avec par exemple uniquement de la variabilité d’architecture, ou sans variabilité Archi et OS), pour vraiment pouvoir statuer sur les liens de variabilité platforme.
Ainsi, la validation de notre hypothèse 2 ne peut pas être prouvée pour le moment. En effet, l’analyse de chaque projet est longue (surtout l’analyse CI) même avec des outils, et nous n’avons pas pu analyser de projets sans variabilité platforme.
Malgré ça, nous pouvons déjà statuer sur l’hypothèse 1.
Si l’on prend les variabilités de platforme de manière générale (architecture et/ou os), il semblerait qu’une variabilité de platforme dans le système implique une variabilité de platforme dans la CI quelle qu’elle soit et inversement.
Or, dans le cas de la calculatrice windows, nous ne pouvons pas prouver de lien entre la variabilité OS du système et la variabilité d’architecture de la CI.
Il faut donc bien différencier OS et architecture dans notre analyse. Et en analysant le tableau d’association, il n’est pas possible de prouver les équivalences suivantes:
| Système | CI | |
|---|---|---|
| OS | <=> | OS |
| Archi | <=> | Archi |
| OS+Archi | <=> | OS+Archi |
Ainsi le lien entre les variabilités platforme CI et système ne semble pas exister, donc notre hypothèse 1 n’est pas valide.
Ainsi, notre hypothèse n°2 n’est pas vérifiable, et la n°1 n’est pas valide. On ne peut pas prouver de causalité directe entre la variabilité plateforme d’une CI et celle de son système.
Cette conclusion n’est pas définitive, il nous faudrait tester plus de projets, avec des critères de variabilités plateforme différents, pour confirmer ces propos.
Pour extraire les données dont nous avions besoin pour les projets. Nous avons créé des scripts python qui analysent les résultats de cppstats pour en sortir nos metrics. Vous pourrez y accéder dans les assets du projet.
[1] J. van Gurp, J. Bosch, and M. Svahnberg. 2001. On the notion of variability in software product lines. In Proceedings Working IEEE/IFIP Conference on Software Architecture, IEEE Comput. Soc, Amsterdam, Netherlands, 45–54. </br> [2] (Hunsen, C., Zhang, B., Siegmund, J., Kästner, C., Leßenich, O., Becker, M., & Apel, S. (2016). Preprocessor-based variability in open-source and industrial software systems: An empirical study. Empirical Software Engineering, 21(2), 449-482.) ###Projets </br> FreeBSD: FreeBSD src tree </br> Redis: redis/redis: Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps.</br> OpenVPN: OpenVPN is an open source VPN daemon</br> OpenCorePkg: OpenCore bootloader (github.com)</br> Microsoft Calculator: Windows Calculator: A simple yet powerful calculator that ships with Windows (github.com) </br>